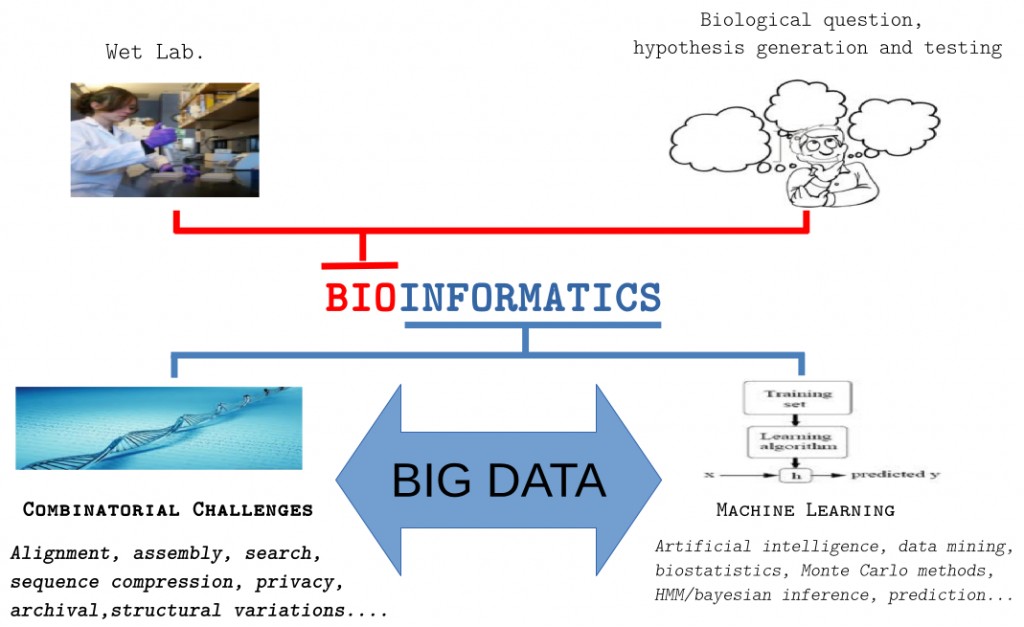
High-throughput DNA sequencing equipments produce huge volumes of data and the cost of sequencing drops rapidly. Thus, very soon the machines will be producing more data than we can process. We are mostly interested in the design and implementation of the tools targeting combinatorial challenges in bioinformatics such as:
Alignment
Map billions of short reads onto a given reference genome.
Assembly
In case no reference is available (De Novo sequencing), solve the puzzle with billions of pieces.
Compressive Genomics
Keep the sequence data in compressed form such that further processing on the data can be performed without decompressing it. See the article here for more details. In that sense, we study compressing biological data while providing efficient random access and retrieval.
Biological Databases
Design and implementation of databases for storage, retrieval, display, analysis, search of biological (particularly omics) data as well as exchange and communication between such resources.
Secure and privacy-preserving biological data processing
How can we store our sensitive biological data in a cloud-computing environment securely without sacrificing efficient processing capability.