1. Introduction
With the explosive growth of the Web, we are increasingly moving towards a fully connected world. Started as merely an information access mechanism, the Web is now fundamentally changing the way we live our lives by providing multimedia communications and electronic commerce. The success of the Web has demonstrated that the power of being connected can drive innovations and create new applications beyond one’s imagination.
As broadband communications are being brought to the homes in an accelerating speed and as small handheld devices are getting smarter, more popular, and better connected, the notion of being able to communicate with anything that one cares at any time from anywhere will become a reality. In this big picture, home networking is a natural next step in which both existing devices and future smart appliances are fully connected inside the house and accessible to the homeowners whenever needed. Just like the evolution of the Web, the most basic home networking applications have first emerged and the power of being connected is now paving the way for unlimited future innovations. Starting from the simple scenarios of sharing files, printers, and Internet connections, home networking is also moving towards enabling multi-PC games, digital video and audio anywhere in the house, device automation, remote diagnosis of out-of-order home appliances, etc.
An interesting observation is that, in the home networking domain, different people have dramatically different ideas on what the killer applications should be, depending on their life styles. An informal survey shows that, while some people are most interested in the ease of operations of their A/V equipments and rich multimedia entertainments in general, other people are more concerned about the security and safety of their houses and would like to be able to remotely monitor their houses, control the appliances, and get notified when something bad happens. So it seems that the most fundamentally important thing in home networking is to provide the infrastructure for device connectivity and let people design their own killer applications on top of the infrastructure.
In the Aladdin project, we focus on providing the system infrastructure for device connectivity by integrating the seven in-home networks into one dependable home network: powerline, phoneline, RF (radio frequency), IR (Infrared), A/V LAN, security, and temperature control. The goal is to allow the users to plug in a device on any of these networks and make it part of the Aladdin system that can be used in conjunction with all the other devices to accomplish higher-level system or user-directed tasks. To make the whole system good enough to live, one must pay special attention to the dependability issues, including reliability, availability, security, and manageability. The second goal of the Aladdin project is to support dependable remote home automation and sensing. We believe that the true value of home networking is when people are away from their homes. Therefore, providing reliable and secure remote access to home networks and providing reliable sensing and controlling of devices are important parts of the project.
From dependability point of view, home networking introduces several new challenges. First, in the consumer electronics market, having volumes in order to drive the price down is a key to success. A good way to achieve that is to package the products as add-on modules with primitive I/O specifications so that they can be used with a variety of different systems and can be added incrementally to existing systems to control new or existing devices. However, such a design creates dependability problems that must be dealt with by the systems. The powerline-based modules and sensors, which will be described later, are good examples. Second, home networks are heterogeneous and dynamic. Each of the in-home networks has a different characteristic in terms of bandwidth, connectivity, security, interferences, etc. One can often exploit the redundancy provided by one network to solve dependability problems faced by another network. In addition, compared to the machines in the enterprise environment, consumer devices in the home networking environment are more dynamic in terms of mobility, availability, and extensibility. The system must be able to keep track of all the changes in the entire network in a robust manner. Finally, human administrators in the enterprise domain can be smarter than the systems themselves in terms of failure diagnosis and recovery, and intrusion detection and defense. But, in the home networking domain, the systems must be smarter than the average homeowners in dealing with those issues.
To address the above issues, the Aladdin system makes heavy use of lookup services that are built upon the concept of Device Address Book (DAB). Each device can have multiple "addresses" and can be reached by any of multiple control programs through potentially different programming abstractions (e.g., distributed objects, wire protocols, etc.) and programming paradigms (e.g., synchronous calls, queued operations, etc.). At the center of the Aladdin system is an extensible dependability framework for facilitating end-to-end system stabilization. The lack of system administrators require home networking systems to be self-healing. However, since consumer devices fail more often and with more different modes, and intrusions and interferences can come from different networks, one must ensure that potentially concurrent recovery actions do not interfere with each other and bring the system to an unrecoverable state. Instead of devising protocols to solve each individual dependability problem separately and then prove the interference freedom among them, we have built a dependability framework as a shared infrastructure to simply the design, implementation, and proof of correctness of protocols. The infrastructure is essentially a soft state store with an eventing mechanism, where the term "soft state" is defined as volatile or nonvolatile state that will expire if not refreshed within a configurable, pre-determined amount of time. We will demonstrate the advantage of soft state in terms of simplifying consistency maintenance and failure recovery of lookup services and improving the efficiency of stabilization. As new devices are added to the system and as new dependability problems are observed, the framework also provides the extensibility to incorporate new protocols and facilitate the proofs that they do not interfere with existing system stabilization.
The paper is organized as follows. Section 2 gives background on phoneline networking, powerline networking, Distributed Component Object Model (DCOM), the distributed object system that we use, and self-stabilization. Section 3 describes the overall architecture and the deployment of the Aladdin system. Section 4 presents the underlying dependability framework and how it is used to solve the various dependability problems that we have experienced in the deployment. Section 5 discusses related work. Section 6 concludes the paper and summarizes future work.
2. Background
2.1. Phoneline Networking
To provide in-home networking without requiring the rewiring of the houses, the Home Phoneline Networking Alliance (HomePNA) was formed to create de facto standards that leverage the existing phoneline [HomePNA98]. Commercial products based on Tut Systems’ technology are now available for providing essentially 1Mb/s Ethernet over the phoneline. The technology occupies the frequency range between 5.5MHz and 9.5MHz, and can coexist with standard voice communication (20Hz to 3.4kHz) and xDSL services (25kHz to 1.1MHz) without interference. Products based on the new 10Mb/s Ethernet technology are expected to emerge in the near future to enable in-home multimedia communications.
2.2. Powerline Networking
Powerline networking is likely to be an essential part of any home networking systems because it provides the most ubiquitous wired connectivity throughout the majority of the houses. However, due to the quality of the physical wiring and the inherently less secure connection topology, commercial powerline networking products have not made as great progress as their phoneline counterpart in terms of both the bandwidth and the programming abstraction. In the current Aladdin prototype, we use the X10 powerline control protocol and devices because they are the most consumer-ready products at this point. With the understanding that X10 has a few inherent weak points and so their uses in controlling more critical home appliances will most likely be replaced by some next-generation powerline networking protocols, we will separate our discussions of powerline dependability into generic powerline issues and X10-specific issues.
The X10 protocol transmits binary data over the powerline by using a 120kHz signal burst for 1 ms at the zero-crossing point of the 60Hz AC sine wave. In most cases, PCs communicate with the CM11A computer interfaces [CM11A] through the serial ports, and the computer interfaces generate the corresponding X10 signals. In addition to using the standard X10 code for device control, we also use the extended X10 code to transmit small amounts of data bits for device announcements and failure detection.
An X10 module usually has two dials on its surface: the House Code Dial and the Unit Code Dial. To assign an address to an X10 module, the user selects one of the 16 house codes ranging from A to P by setting the House Code Dial, and selects one of the 16 unit codes ranging from 1 to 16 by setting the Unit Code Dial. Overall, there can be 256 distinct X10 addresses (A1 through P16) that respond to different X10 commands over the powerline. Some products have expanded the set of addresses by using the extended X10 code.
Figure 1 illustrates the most commonly used X10 modules. Lamp modules respond to X10 On, Off, and Dim commands. Appliance module respond to only the On and Off commands. Universal modules provide a contact closure in response to the On command. Powerflash modules send an X10 command when a contact closure is made or a low voltage is applied to their terminals. RF transmitters send a wireless extended X10 signal when a contact closure is made to their terminals. Such RF signals are received and converted to wired X10 signals by the same kind of RF transceivers that respond to the remote control command made by the users. Similarly, PCs can communicate with the CM17A computer interfaces through the serial ports to generate wireless X10 signals [CM17A].

Figure 1. Common X10 devices and their interactions.
2.3. Distributed Component Object Model (DCOM)
DCOM is an object-oriented Remote Procedure Call (OORPC) system that extends the benefits of object-oriented programming to networked environments. To simply distributed programming, traditional RPC systems provide the infrastructure for dispatching, security, threading, connection management, etc. to hide the low-level communication details from the programmers. DCOM augments RPC with the concept of objects with multiple interfaces and a mechanism for remote activation. Typical DCOM client-server interactions proceed as follows. The client application invokes the CoCreateInstanceEx() API to either activate a server application or connect to a running server process. The client specifies a Class ID (CLSID) for the requested object and the Interface ID (IID) of the interface to which it is requesting a pointer. As a result of this activation, the server process creates an object instance of CLSID and (logically) returns to the client a pointer to the object’s IID interface. The client can then invoke methods through that pointer as if the object resides in the client’s own address space. When the client needs a pointer to another interface of the same object instance, it makes a QueryInterface() call on the current interface pointer and supplies a new IID.
2.4. Overview of the Aladdin System
2.5. Deployment
The first prototype of the Aladdin system has been deployed in the Aladdin House, a 3,900-square-foot house with two floors and a ground-floor garage, located in south Bellevue, Washington. At the heart of the system are six Windows 98 PCs (three desktops and three laptops) deployed in the family room, den, bonus room, master bedroom, kitchen, and garage. Each PC, referred to as an Aladdin node, is designed to be a semi-intelligent node equipped with the following consumer electronic devices: a phoneline networking adapter [AnyPoint99] for connecting to the 1Mbps phoneline Ethernet backbone; a CM11A computer interface [CM11A] for powerline monitoring and control; a CM17A computer interface [CM17A] for wireless powerline control; a wireless motion sensor for detecting local motions; and a USB camera for recording snapshots and video clips of local activities. Optionally, some of the PCs are also equipped with an infrared (IR) transceiver [Slinke] for communicating with IR-based A/V equipments.
At the other end of the distributed system are devices and sensors. The current configuration has 25 devices including lamps, ceiling lights, fans, pumps, VCRs, garage door openers, etc. PCs and the CM11A interfaces are also treated as powerline-controllable devices to allow remote reboots, as will be discussed later. In addition to the motion sensors, there are 10 other sensors including water sensors, temperature sensors, AC current sensors, horizontal/vertical position sensors, magnetic contact sensors, power outage sensors, etc.
2.6. System Components
The current focus of the Aladdin project is on providing dependable home automation, including remote home automation. There are four major components in the system architecture: device announcements for devices to join and leave the system, lookup services for client applications to find target devices, remote access front end for receiving and processing remote home automation requests, and system management daemons for monitoring and handling dependability problems in the entire system. Figure 2 illustrates the device announcement mechanisms and the registration side of the lookup services. The Attribute-Based Lookup Service (ABLS) is responsible for maintaining the availability information of all hardware devices and software modules and their associated attributes. The Name-Based Lookup Service (NBLS) is used to maintain the addressing information of all available running object instances.
Through the ABLS administration console application, the user performs a one-time manual task of assigning a unique address to each power outlet, wall switch, etc. that the user would like to control remotely. The current system uses the X10 addresses as the unique addresses. For example, the X10 address “K3” may be assigned to an outlet on the family-room side of the kitchen on the first floor. In the ABLS, the outlet then has a database entry with “X10Addr=K3”, “floor=1”, “room=kitchen”, and “side= family_room”. For fixed devices such as wall switches, the additional “device” attribute can be manually entered to associate it with the physical-location attributes. For dynamic devices such as a floor lamp, the “device=lamp” attribute is announced when the lamp is plugged in and switched on, and the registration with the ABLS is performed automatically by proxy controllers (usually PCs) that receive such announcements. (See the descriptions of the Aladdin Device Adapter for more details.) Smart devices such as PCs perform registrations on their own behalf. They are also responsible for registering their peripherals. Computation objects such as language parsers and speech recognizers are also registered in a similar fashion. The interface IDs they support are registered with the ABLS during the software installation process, while the pointers to object instances are registered with the NBLS when objects are instantiated and available to receive requests.
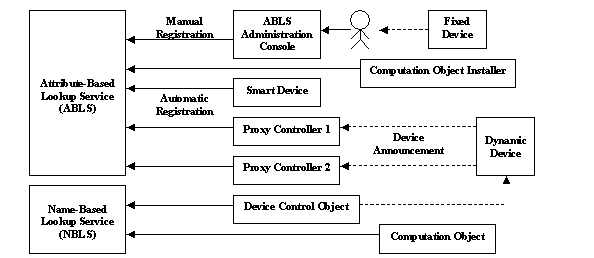
Figure 2. Device and object registration with the lookup services.
Figure 3 illustrates the interactions among system components for email-based home automation. At the front end, the email-reading daemon periodically dials up to the Internet Service Provider (ISP) to retrieve digitally signed and encrypted emails containing home automation requests. After validating the signature on an email, the daemon passes the request to a natural language parser to convert it into an action and a list of attribute-value pairs. For example, the request “Turn off all second-floor lamps” gets parsed into “action=off” and “device=lamp AND floor=2”. These attribute-value pairs are then submitted to the ABLS to find all matching devices, each of which is identified by a unique name, for example, A2_lamp. To control each matching device, the daemon queries the NBLS with the device’s unique name and gets back a list of addresses that can be used to locate the appropriate device control objects. Upon receiving a call from the daemon, an object sends control signals to the target device and receives feedback signals from the sensor(s), if available, to confirm the action. The various system components in Figure 3 can all be running on different PCs, depending on the load distribution and machine availability. It is the responsibility of the system management daemons to ensure that all the components are always available to carry out the requested actions in spite of machine or network failures.
In addition to the above on-demand control scenarios, event notification is another very useful system functionality. When any of the sensors detects an anomaly, it will notify the system, which then either generates an audio or video alarm or sends an email to notify the homeowner. The main server, located in the family room and connected to a low-cost UPS (Uninterruptible Power Supply), is responsible for detecting power outages and sending an emergency notification email.
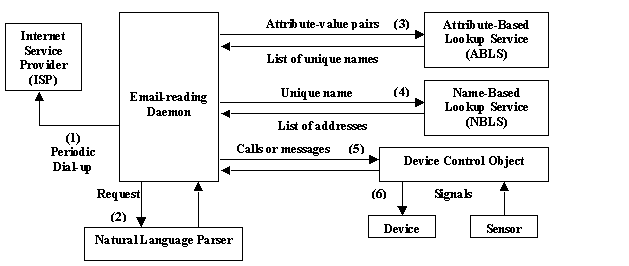
Figure 3. System architecture for email-based remote home automation.
3. Dependability Issues and Framework
The task of the system management layer of Aladdin is to ensure the dependability of the ABLS and NBLS lookup services, as well as the dependability of the computation and communication resources that are needed by device control objects. In this section, first, we describe the sources of undependability in the Aladdin environment, which make the design of the system management layer challenging. Then, we describe the stabilization-based approach that we have adopted to provide dependability in the presence of these sources. Finally, we present an extensible framework than facilitates implementation and validation of the stabilizing daemons that comprise the system management layer. The details of the daemons follow, in the next section.
3.1. Sources of Undependability
Aladdin is subject to a wide range of undependability sources. Some of these sources are non-obvious and were observed only during actual system deployment. They are roughly divided into four categories.
(1) PCs: it is not uncommon for consumer PCs to hang or crash. We also observed that some PCs may hang during a reboot and require multiple power cyclings to bring them to the working state. It is also not uncommon for consumer PC peripherals to become inaccessible, for example, when some zombie processes hold on to the locks. Individual processes, in particular the essential system management daemons, may also hang. Over time, the local system clocks drift from real time.
(2) Networks: on the powerline, power outage is an obvious problem. Security, signal attenuation, and line noises are generic powerline networking problems. We also observed that a faulty powerline transmitter can flood the network with random (but valid) powerline commands, and RF transceivers can saturate the network in response to RF interferences. Intruders may attempt to exhaustively try all potential powerline commands. Finally, X10-specific issues include signal collisions and non-atomic command transmissions.
On the phoneline, environmental problems such as excessive moisture can disrupt certain part of the communication links. Partitions can happen, for example, when the connections to phone jacks or phoneline adapters become loose, or when the adapters hang.
(3) Devices: on the powerline, devices can be switched off accidentally, unplugged, or broken and no longer be controllable by the system; battery-powered sensors can cease to work when the batteries run out. We also observed that CM11A computer interfaces can hang, for example, when incoming signals interfere with outgoing signals.
(4) Services: Intruders may gain attempt to gain access to a homeowner's desktop or laptop PCs. (In addition to the standard security mechanisms such as digital signatures and encryption, Aladdin employs additional application-level security to prevent intruders who gain access from gaining control of the house. Due to space limitation, we do not discuss this subject any further in the paper.)
3.2. Stabilization
The system management layer has to ensure dependability in the presence of any number of the many undependability sources mentioned above, although for the more severe ones it may only be able to provide a degraded mode of Aladdin operation. Dealing with each undependability source in isolation is clearly insufficient: if multiple faults occur simultaneously or if, during recovery from one type of faults, faults of another type occur, little is guaranteed about the computation of the system as a whole. A systematic approach to dependability design is therefore warranted.
Stabilization is the approach we have chosen for dependability in the system management layer. Stabilization means that if the system is placed in an arbitrary state, it eventually reaches a state from where the system computation is as desired. The assumption that the system may be placed in arbitrary state models the effect of the occurrence of faults, intrusions, delays, etc. on the system state. This assumption is justified, theoretically, by results that show that process crashes and network faults can drive systems into arbitrary states [GV97] and, practically, by the difficulty/cost of enforcing tight boundaries on the system states in the presence of many, often-unpredictable sources of undependability. The requirement that the system eventually resumes desired computation is made practical by attempting to minimize the convergence time and the space redundancy and to maximize the convergence locality (so state perturbations that affect only small regions are corrected without affecting large regions).
By way of contrast, an alternative approach to dependability is to mask all sources of undependability. Masking means that the system computation is always as desired, and hence the system must remain within a tight boundary of system states in the presence of faults. Unfortunately, as mentioned above, cost limitations make it impractical to assume the level of spatial redundancy in PCs, peripherals, and devices that enable masking. Moreover, the temporal overhead of ensuring that every user request is handled correctly, e.g. by using transactions, adversely affects system performance. A more cost-effective alternative is to fail-stop the system when faults occur. Even if the system loses availability in the presence of faults, its computations are always safe. This approach demands that homeowners deal with the failures. Assuming expertise in homeowners does, however, significantly limit the adoption of home automation systems.
As deployed in Aladdin, the notion of stabilization has one difference from its usual formulation [A99]. Typically, the system computations in the absence of any faults define the desired computations that a stabilizing system must converge to. In the presence of severe perturbations, however, it may be impossible or impractical to converge to this set of computations. For example, an undetectable intruder flooding the powerline network may deny restoration of services that use the powerline, so the best that can be hoped for is to deny these services to the intruder as well. Therefore, we consider a hierarchy of desired computations, and allow the system to converge to those computations in this hierarchy that it can recover to most effectively. This generalization is sometimes called pseudo-stabilization [BGM95].
Component-based Stabilization: Correctors. Transforming a non-stabilizing system into a stabilizing one is achieved by adding a special-purpose dependability component, namely a corrector. A logical condition on the system state is associated with a corrector, which we refer to as its correction predicate. If the correction predicate is ever violated, the corrector is tasked with restoring the system to a state where its correction predicate holds. Once restored, the corrector eventually witnesses this restoration to the system by signaling another logical condition, which we refer to as its witness predicate. Intuitively, the witness predicate is needed since the correction predicate may be a condition on the global state of the system and hence cannot be observed instantaneously by the system. As can be expected, system computation when the witness predicate is false is not guaranteed to be as desired.
A subtle point in the use of the correctors (which is true in fact for all dependability components) is that they must deal themselves with the faults that the system is subject to. In particular, this means that a corrector must itself be stabilizing, i.e. it must satisfy its specification eventually upon being placed in an arbitrary state. Likewise, if a corrector is designed using a smaller component whose task is to detect the violation of the correction predicate, which we refer to as a detector, then that detector must also itself be stabilizing. The interested reader may find a detailed discussion of the role of detectors and correctors in [A98].
We are now ready to formally define stabilization and correctors. Let p be a system. A state of p is defined by a value for each variable of p chosen from the predefined domain of the variable. A state predicate of p is a boolean expression over the variables of p. A computation of p is a maximal sequences of states s1, s2, … such that for each j, j > 0, sj is obtained from state sj-1 by executing an event of p. Maximality of the sequence means that if the sequence is finite then no event of p can execute in the final state. A state predicate, U, is an invariant of p iff all computations of p that start from a state where U holds satisfy the specification of p.
A corrector is defined by four arguments: A correction state predicate, X, a witness state predicate, Z, a correction protocol, c, and an invariant state predicate, U. Upon starting from any state where U holds, every computation s1, s2, … of c satisfies the following four conditions.
· (Safeness) For all i, i³ 0, if Z holds at si then X holds at si. (In other words, U Ù Z Þ X.)
· (Stability) For all i, i³ 0, if X holds at si then X holds at si+1.
· (Convergence) There exists i, i³ 0, such that X is true at si .
· (Progress) For all i, i³ 0, if X is true at si then there exists j, j³i, such that Z is true at sk, for all k, k³j.
From Stability and Convergence, it follows that a corrector eventually reaches a state where X is truthified and X continues to be true thereafter. Moreover, from Safeness, it follows that a corrector never lets the predicate Z witness the correction predicate X incorrectly. From Progress, it follows that a corrector eventually reaches a state where Z is truthified and Z continues to be true thereafter. Of course, if the faults falsify X, then subsequent execution of the corrector should truthify X again and then eventually reassert Z.
A special case of correctors deserves mention here. This case deals with ensuring that communication protocols, say over powerline or phoneline networks, yield only desired communication behavior. Here, instead of formulating the correction state predicates using history variables that record all communications, we formulate them using regular expressions over the events (in this case, messages) that have occurred in the past time interval of a predefined length. An example of so-called event-path correction state predicates is:
DS : Ø ( (Message* ; Invalid_Message ) K ) ,
which expresses the predicate that in the last DS time interval the number of Invalid_Message occurences is not K (in fact the number must be less than K , since an Invalid_Message is also a Message). Recall that regular expression E* denotes 0 or more occurrences of expression E. E + denote 1 or more occurrences of E. E K denotes K occurrences of E. E; F denotes E sequentially composed with F. E ; F denotes E followed by F. And E + F denotes E or F (nondeterministic choice).
Just as a system can be made stabilizing by adding correctors, its components (i.e. its system daemons and, at a finer granularity, each of the protocols in its system daemons) can individually be made stabilizing by adding correctors. By way of example, recalling the sources of undependability described above, undependability associated with the PCs may stabilized by correctors that perform self-monitoring, self-diagnosis, and self-recovery, so as to automatically bring any failed component back to service whenever possible. Faulty powerline transmitters and interference-prone RF transceivers are addressed using event-path correctors that detect "bad" patterns and initiate diagnosis and recovery actions. Signal collisions and non-atomic command transmissions are addressed using protocols provide collision avoidance and atomicity. Powerline outages are addressed using correctors that enable critical devices to be accessed in a degraded mode. Phoneline faults are addressed using correctors that detect them, and either correct the fault if possible or enter a degraded mode of operation if the faults are persistent. Devices and sensors that are offline or have failed are detected and excluded from the lookup services to maintain consistency. Hanging CM11 interfaces are detected and power-cycled to maintain the availability of powerline controls.
3.3. Soft-State Store: An extensible dependability framework
Motivation. Dependability in Aladdin is provided by a set of lookup services and management protocols (Figure 4). The design of these services and protocols is complicated not only because they share resources but also because they must collectively stabilize system computations to acceptable ones in the presence of the complex failure modes discussed above. Another key design complication is the need for system extensibility: the design must facilitate the systematic addition of new management protocols, e.g. next-generation powerline network protocols, without interfering with existing management protocols, e.g. X10, and without compromising system dependability. A different sort of extensibility further complicates the design: system administrators may specify new rules for device control based on the passage of time and observation of certain events, which must be automatically enforced by the system. For these reasons, a systematic design, implementation, and validation approach is crucial for Aladdin dependability.
Concepts. We systematize design by separating functionality and dependability issues. Specifically, the service or protocol at hand is designed first, and then augmented with dependability components. Stabilization being our chosen form of dependability, the added dependability components are all correctors. If no failures occur, the correctors do not affect the normal computation of the underlying program. When failures occur, the correctors ensure that the underlying program eventually resumes its normal computation or, depending on the severity of the failure, an acceptably degraded version thereof.
We systematize implementation by defining and implementing a Soft-State Store (SSS). The central idea of SSS is to decouple the producers and consumers of dependability related information and to remember the most recent information values. More specifically, instead of directly communicating information from correctors or their underlying programs to other correctors or their underlying programs, information is published to SSS, which updates its stored value for that information and notifies the corresponding subscribers. SSS also lets subscribers poll the stored value of information. SSS maintains the validity of the stored value by associating a timebound with it. If the stored value is not updated within its associated timebound, it disappears --hence the term soft-state. The separation of producers from consumers facilitates extensibility: new producers and consumers of information are readily incorporated. The maintenance of soft-state distinguishes SSS from pub/sub eventing, and is crucial for implementing stabilization. A characteristic of stabilization is that failures may prevent consumers from receiving or processing some information changes, but convergence to acceptable computations is facilitated by maintaining soft-state and repeatedly polling it. By way of contrast, were the information to be stored in hard-state, it could be arbitrarily out-of-date and potentially complicate the convergence.
 |
Separation of correctors from protocols/services and SSS-based propagation of dependability related information systematizes the validation of Aladdin. If no failures occur, validation reduces to ensuring that the protocols/services satisfy their functionality. When failures occur, validation reduces to ensuring that all correctors eventually satisfy their specification; once all corrections have taken place, the protocols/services proceed as intended. Ensuring that all correctors eventually satisfy their specification requires that eventually the rest of the system stops interfering with each corrector; by virtue of basing the implementation on SSS this analysis is simplified to analyzing the dependences between the information items stored in SSS.
Figure 4. Dependability framework: protocols and correctors are separated; information exchange is via SSS.
4. Aladdin Management Daemons
4.1. Powerline Networking Dependability
4.1.1. Dependability issues in powerline networking
Overview. Due to the quality of the physical wiring and the connection topology, powerline networking suffers from more dependability issues than phoneline networking. As a result, the progress of the powerline networking industry has not been as advanced as that of the phoneline networking industry. In this subsection, we discuss generic issues with powerline networking. Additional X10-specific issues will be discussed later.
Security is probably the No. 1 concern. Most houses share the same powerline subnet with some neighboring houses. Powerline commands from one house can potentially reach the devices in another near-by house and interfere with the controlling of those devices. Conversely, powerline commands and device announcements from one house can potentially be monitored by another house, thus creating privacy concerns. A canonical solution to this problem is to rely on digital signatures and encryptions. But the limited bandwidth currently achievable by commercial products poses a challenge to the applicability of this solution.
Reliability is also a big issue in powerline networking. Powerline control modules are delicate electrical components and, since they are directly plugged into wall outlets, they are susceptible to the damage by voltage spikes. Signal attenuation may prevent powerline commands generated by a controller connected to one circuit breaker from reliably reaching the target device connected to another circuit breaker. Line noises generated by some household appliances or external sources may transiently interfere with the operation of powerline controls. Finally, since the most common usage of powerline networking is to enable wireless remote control by the users, one or more RF transceivers as shown in Figure 1 are almost always present. Unfortunately, such transceivers also provide another channel for RF interferences to cross the threshold the powerline and create either transient, intermittent, or persistent reliability problems.
System architecture for dependability enhancements. In our current deployment, we installed an X10 signal blocker at the main electrical panel to block X10 signals from coming into and leaving the house. For critical devices such as the garage door opener, we take advantage of the more secure phoneline to provide additional security. Instead of being connected to the common powerline network, each such device resides on a private powerline network essentially configured as a PC peripheral. The private powerline network is constructed by using an X10 signal filter to isolate a power strip from the common powerline. For example, the garage door opener resides on a private powerline network that is configured as a peripheral of the garage PC. To remotely control the garage door opener, one must go through the phoneline Ethernet to reach the garage PC and send out an X10 command from there. Even as the next-generation powerline networking protocol provides better and better security, the concept of exploiting multiple redundant networks to provide additional security remains valuable.
On the reliability side, we installed a whole-house surge protector at the main electrical panel to absorb potential power surges. The problem of signal attenuation is quite serious. Since we have six PCs throughout the house, we configured them in such a way that any device can be reliably reached by at least two PCs and so the control operation can tolerate any single machine failures. This is another example of exploiting multiple redundant networks: when one machine cannot reach a device on a certain part of the powerline network either due to permanent partition or transient interference, it can route the command over the phoneline to another machine and send powerline signals from there. Recall that the ABLS maintains a list of multiple controllers for a single device. So, a controller program can simply enumerate through that list to try different routes until the operation succeeds.
Powerline-based motion sensors introduce potential reliability problems for powerline networking. Since they are designed to quickly detect motions and fire events by sending powerline commands, having multiple motion sensors in the presence of persistent motions can exhaust the already limited bandwidth and cripple the powerline network. Our solution is to place each of them on a separate private powerline network as mentioned above, and let each PC be responsible for recording its local motion sensor state. These sensor states are then propagated to other nodes as part of the soft-state exchange protocol in the dependability infrastructure.
Finally, we have observed reliability problems associated with powerline transmitters. For example, during a 24-hour period, one of the wireless transceivers kept receiving RF interferences that resembled valid X10 wireless signals. As a result, it kept converting those interferences to powerline signals and consumed all the bandwidth. In another incident, a faulty CM11A interface kept generating random X10 signals, again saturating the powerline. These observations suggested that the transmitters should not be directly plugged into the powerline without a cutoff mechanism. In the current deployment, every transmitter on the common powerline network is plugged into an X10 receiver so that the system diagnosis protocol can cut the transmitter off the network if it is causing reliability problems.
4.1.2. Powerline monitoring and diagnosis
To deal with the powerline security intrusion, packet collision, wireless transceiver interference, and faulty CM11A interface problems discussed above, Aladdin uses event-path correctors. Bad powerline communication patterns on the powerline are expressed as event-path predicates. Specifically, the event-path predicates “more than K invalid commands transmitted on the powerline within the last DS time” and “more than L non-null commands repeated on the powerline within the last DT time” are used to detect intrusions. The event-path “more than M interfering commands transmitted on the powerline within the last DU time” is used to detect wireless transceiver interference. And the event-path “more than N random commands transmitted on the powerline within the last DV time” is used to detect faulty (potentially disconnected) interfaces. An example of the formal expression of the first event-path is:
DS : ( Command* ; Invalid_Command ) K .
Detection of these event-paths is performed at all nodes, to avoid scenarios where partitioning or attenuation prevents some nodes from successfully monitoring the bad patterns. Correction is performed at only one node, to avoid having to synchronize concurrent corrections. The correction protocol is as follows. Periodically, the correction node broadcasts a request to all nodes to obtain the witness predicates of their respective detections of bad event-paths. If the collection of the witness predicates of all nodes shows a bad pattern has occurred, the correction node then broadcasts a message to all nodes to halt their detection; it then issues a correction command corresponding to the bad pattern and, finally, broadcasts another message to all nodes to resume their detection. Specifically, the correction action “send null commands repeatedly” is used to deal with intruder traffic, by exhausting the powerline network bandwidth. The correction action “power off transceivers one-by-one until the repeated Dim commands disappear” is used to deal with faulty transceivers. And the correction action “power off CM11A interfaces one-by-one until the repeated random commands disappear” is used to deal with faulty CM11A interfaces. Note that these correction actions are not atomic operations: the first one generates continuous traffic, and the remaining two exhaustively choose a “candidate” faulty component, power it down, and then test whether the candidate had indeed been responsible for the bad pattern. The test itself uses the same protocol messages to solicit/send witness predicates and to halt/resume detection.
What role does the stabilization of the powerline correction protocol play? As we shall discuss below, stabilization enables the protocol to survive the failure of the phoneline network, the corruption of the phoneline adapters, and failures of the detection nodes and the correction node. Moreover, it also enables the protocol to deal with situations where nodes are rebooted by the system diagnosis protocols during its execution.
4.1.3. X10-specific control
In addition to generic powerline dependability issues, X10 has two particular dependability problems. The first is the inability of X10 to deal with packet collisions resulting from concurrent transmissions, which necessitates control of nodes to avoid concurrent transmissions. In Aladdin, we have implemented collision avoidance using a stabilizing token ring protocol over the phoneline network.
The second problem is the inability of X10 to provide atomic delivery of X10 commands, which are a sequence of packets. Partial delivery of X10 commands can yield unpredictable results, in the following sense. X10 commands all have the form: ádevice_addressñ+ ; ádevice_functionñ, i.e., one or more device addresses followed by a device function which is to be applied at all of the addressed devices. If some of the device addresses are lost due to collisions, then the device function is applied at only the rest of the addressed devices. Worse, if the device function gets lost, then the addressed devices may execute the device function of the next command that is successfully transmitted. We ensure transactional semantics by adding an event-path corrector that monitors each command transmission and issues a compensating transaction in case the command is transmitted only partially. We also implement correctors that deal with loss of synchronization between nodes and CM11A interfaces. We elaborate on these correctors as well as the token ring protocol, next.
Self-stabilizing token ring. Token passing is a well-known way of serializing access to a shared medium, and stabilizing token ring protocols are readily available. We selected Dijkstra’s K-state stabilizing token-ring protocol, which is asymmetric in that one node is distinguished as the leader. Since Aladdin nodes can fail and reboot at any time, we introduced underlying correctors that (a) reselect the leader node and (b) reconfigure the ring, as need be. Both correctors are based on the idea that each node periodically broadcasts heartbeat messages containing the node ID and that this information is maintained in the SSS at all nodes. Selecting the distinguished node simply reduces to selecting the node with the highest ID in the SSS. Reconfiguring the ring simply reduces to each non-leader node choosing its predecessor to be the node in the SSS with the highest ID that is lower than its ID and its successor to the node with the lowest ID that is higher than its ID. (The leader node chooses its predecessor to be the node with the lowest ID and its successor to be the node with the highest ID lower than its ID.)
While stabilization simplified the leader election and ring reconfiguration tasks, one might wonder what is the benefit of stabilizing the token passing itself. In particular, what is the benefit of dealing with arbitrary states of the token ring, such as ones with multiple tokens? Consider the scenario where simultaneous reboot of multiple nodes or partitioning of the network yields multiple rings, each with a few nodes and a token. In this case, should the rings merge, multiple tokens will likely result. Designing the reconfiguration correctors to eliminate extra tokens during the merge is not straightforward, because node failure and reboot may occur during reconfiguration itself.
Stabilizing packet transmission. Synchronization between a node and its CM11 interface is simplistic: If the interface receives an X10 packet on the powerline, it repeatedly sends “ring” signals to the node and waits for a response. If the node wishes to transmit, it engages in a handshake where the interface responds with a checksum of the packet in question. During these handshakes, the CM11 interface may lose synchronization with respect to the node, thus successful transmission is not guaranteed. Worse, the interface may hang and need to be power-cycled by transmitting an X10 command via some other CM11 interface. Furthermore, reception dominates transmission, so node transmission may remain indefinitely blocked if an intruder starts transmitting continuously on the powerline. To deal with these problems, we use two CM11A interfaces per node, which interact with the node via a stabilizing synchronization protocol. The two interfaces are used to power-cycle each other as need be. Also, one works in a receive-only mode and the other in a send-only mode, thus guaranteeing nonblocking transmission at each node.
Stabilizing atomic communication of commands. Assuming two CM11 interfaces allows each node to additionally detect whether all the packets in an issued X10 command were transmitted successfully. If not, another stabilizing protocol attempts to retransmit the command. Since, the previous partial command transmission may have corrupted the status of the devices it was addressing, a compensating command is issue prior to the transmission retry, whose net effect is to nullify or complete the previous partial command transmission. Specifically, the compensating command that nullifies a partial command transmission where the device function packet was lost is a no-op function (such as DIM 0%).
4.2. Node Dependability
As mentioned earlier, PCs are subject to various partial failure modes: some PC reboots or shutdowns may hang, some PC daemons may hang, some dependability protocol processes may lose coordination their peers on different PCs, and some PC peripherals (including the phoneline adapter) may hang. To deal with each of these failure modes, every PC monitors its own daemons, peripherals, and neighboring PCs.
Master daemon. The master daemon is at the core of node monitoring. It is minimal by design and robust by implementation, so its hanging is a highly unlikely occurrence. Its tasks include: periodic broadcast of heartbeat messages on the phoneline network containing its node ID, periodic detection that the dependability daemons for node are working, periodic detection that the phone adapter is working, responding to pings from neighboring nodes via the powerline network (as described in the neighboring node daemon below), and self-reboot when needed.
Specifically, the dependability daemons monitored by the master daemon include the ABLS, NBLS, device, powerline, and phoneline-based SSS information exchange daemons (see Figure 4). For each daemon, the master daemon invokes a corresponding IsWorking() method, and if as a result it detects that the daemon is hanging it attempts to restart the daemon. Daemon restarts are retried if they fail until a retry threshold is exceeded, in which case the master reboots the node.
The periodic detection of the phone adapter is also based on an IsWorking() method invocation. If the phone adapter is not working, the master daemon reboots the node (as current technology does not allow nodes to reset their phone adapter directly). Before the reboot, however, the master daemon halts the dependability daemons and ABLS-disables its associated devices.
Neighboring node failure-detection-and-reboot daemon. This daemon enables working nodes to concurrently detect the failed nodes and to reboot them. Every failed node is dynamically assigned to some working node, as follows. The stabilizing leader election and ring reconfiguration protocols discussed above give each node its predecessor in the ring. Each node assumes responsibility for failure-detection-and-reboot of all the ABLS-enabled nodes whose ID is between that of its predecessor and itself.
For each node k that a node j is responsible for, j follows the following protocol: Since k is not in j’s SSS, j can only conclude that k may have failed, that the phone adapter of k is not working or, in rare situations, that the phoneline network is down. To detect whether k has indeed failed, j adopts the following protocol: j pings k over the powerline and waits for DP time to receive a response. If no response arrives, it sends X10 commands over the powerline to repower k and waits for DQ time to receive the heartbeat from k. If the heartbeat does not arrive, it retries the procedure for rebooting k until a retry threshold is exceeded, in which case it ABLS-disables k. If k has not failed, then upon receiving the ping from j, the master daemon at k invokes the IsWorking() method of its phone adapter to detect whether it is hanging and sends a response to j that includes the status of its phone adapter. Also, as discussed above, if its phone adapter is hanging, k reboots itself; in this case, however, the reboot of k may fail. This possibility is handled by j, which does not try to repower k then, but it does wait for DQ time to receive the heartbeat from k, to determine whether it needs to repower k thereafter.
The reader may wonder whether our node diagnosis solution can be simplified to a non-stabilizing one, say by making each node responsible for failure-detection and reboot of its predecessor node? That solution unfortunately does not handle concurrent failure of adjacent nodes, which may occur when powerline outage is followed by unsuccessful reboots. Even when only one of node reboots unsuccessfully, its previous successor node may no longer have memory of being responsible for rebooting it.
Device daemon. The device daemon monitors all devices associated with a node. The monitoring is analogous to the manner in which the master daemon monitors the dependability daemons. The only difference is that the device daemon needs to interact with the ABLS. In particular, if any ABLS-enabled device cannot be restarted that device is ABLS-disabled.
ABLS and NBLS daemons.
[YI-MIN, WILF]
A leader for NBLS group
A leader for ABLS group
Watchdog and fail-over
4.3. Sensing and controls
Motivation. Since we emphasize remote home automation in the Aladdin project, reliable sensing and controls to provide high-confidence confirmation that the requested actions have been successfully completed are an essential system component. Traditionally, in mission-critical applications, remote automation either relies on a masking reliable sensor abstraction or relies on application-specific knowledge to deal with faulty sensors [NEED REFERENCES HERE]. To provide a masking abstraction, these sensors are highly reliable themselves and support on-demand polling of their current states. The communication media for sensor information collection are highly reliable as well. On top of that, multiple redundant sensors are used together to mask the faults of a subset of the sensors.
Sensors in the consumer electronic market do not satisfy the above requirements. First, these low-cost sensors are not highly reliable. Some of them are battery-operated and so out-of-battery is a common fault. Second, the communication media for sensor event propagation in the home environment are not highly reliable. Most consumer sensors use either the powerline or the RF as the media and are susceptible to signal interference. Most importantly, these consumer sensors do not support on-demand polling of their current states, and this design decision is apparently related to the desire to provide extensibility. Consumer sensors such as the water sensors, magnetic contact sensors, position sensors, etc. usually have a very simple I/O specification: when the environmental factors they are designed to sense change, they provide a contact closure between two wire leads. This simple output model allows them to be connected to any type of downstream systems that can convert this contact closure event to other types of events that are understandable by these systems. For example, in Figure 1, we showed that a water sensor is connected to a PowerFlash module that converts a contact closure event to an X10 command. The same sensor can be connected to any other types of security systems, controllers, etc. as long as they can detect a contact closure.
Unfortunately, such a design for extensibility, which may be necessary in the consumer market to drive the price down, poses a challenge to the issue of reliable sensing. Since the states of the sensors are separated from the converted states in the downstream systems, these two states can potentially diverge and it is not possible to support on-demand polling of the true sensor states. Therefore, it is desirable to provide a system-layer solution that implements a reasonably reliable sensor abstraction in order to simplify application programming.
Design of sensor abstraction. Our system layer solution maintains soft-state for each sensor in the SSS. Control programs using sensors subscribe accordingly to SSS, both to provide on-demand polling of the last known sensor state as well as to obtain sensor update events. Replication of SSS provides redundancy to deal with loss of sensor update events: the SSS of a node periodically multicasts its sensor soft-states, thus the SSS of other nodes can detect missed sensor update events. Sensor update events are transmitted via multiple powerline networks or to both powerline and RF networks provides media redundancy, thus at least some SSS receives these update events.
[[Dropped the Garage door control part; and the comment about adding video feedback clip.–Anish]]
4.4. End-to-End Stabilization
All daemons and protocols in Aladdin are stabilizing not only individually, but also when executed concurrently. Validating this end-to-end stabilization necessitates showing that the daemons/protocols do not interfere with each other. In several cases, a layering argument exists: Lower layers do not depend on higher layers (the converse is not true); hence, the lower layers stabilize independently after which the higher layers can stabilize. For instance, the leader election and ring reconfiguration protocols define such a lower layer. Their stabilization depends only on the availability of the heartbeat information. Higher layer protocols such as powerline transmission, and the neighboring-node diagnosis, etc. depend on these lower layer protocols but do not affect their stabilization.
In other cases, careful validation of interference-freedom is needed: for instance, the powerline diagnosis daemon may disable a misbehaving CM11A interface at a node, but this interferes with the neighboring-node diagnosis, which depends on CM11A interface of neighbors to receive responses to pings over the powerline. These interference problem are solved by constraining our daemons to execute only when some witness predicates provided by underlying detectors or correctors hold. For instance, the neighboring-node diagnosis is constrained to not ping any node when the CM11A interface of that node is ABLS-disabled. Since SSS provides a convenient way of supplying the constraining witness predicates to the daemons in question, the validation of interference-freedom is substantially simplified.
The idea of constraining daemons to execute only when certain witness predicates hold is also essential for dealing with catastrophic events, such as phoneline network failure or power outage. We build detectors for these catastrophic events as follows. Each working node detects phoneline network failure by observing the pings issued by its node diagnosis daemon. When the phoneline network fails, the token ring fragments into a self-loop ring at each node. In this case, the neighboring-node daemon will ping its neighbors over the powerline and receive responses that they (and their phone adapters) are working. If the number of such wasted pings exceeds a threshold over some predefined interval of time, the node can detect phoneline network failure. When power outage occurs, a device that sits between the UPS and a main node detects power outage failure, and this witness information is propagated by the SSS of the main node over the phone line to the other UPS-connected or battery-operated nodes that survive power failure.
Witnesses of phoneline network failure and powerline outage are used to constrain the execution of the neighboring-node daemon and the powerline transmission and diagnosis daemon. Since the token ring fragments when the phoneline network fails, each node has a token of its own and can interfere with other nodes by starting concurrent transmission, correction of CM11A interfaces and X10 wireless transceivers, and reboot of unpowered nodes. We avoid these interferences by letting the daemons execute only if the witness for phoneline network failure is not true or (if it is) then the node is the unique one that owns the ABLS. Likewise, we allow these daemons to proceed only if the witness for powerline outage is not true. The net effect of these constraints is that end-to-end stabilization in Aladdin is preserved even if catastrophic events occur, but as we had discussed earlier Aladdin stabilizes to degraded computation.
5. Related Work
- Jini [Waldo99]
- CAN papers
- COM's running object table, CORBA Name Service and Trader Service
- Group communications
- SSDP, SLP
- Berkeley lookup service paper http://ninja.cs.berkeley.edu/overview.html
http://iceberg.cs.berkeley.edu/publications.html
- Xerox Parc ActiveBadge and ParcTAB papers
[ANISH]
- FTCS distributed diagnosis papers
- classical control theory solutions
- Discrete Event Systems
- Reliable sensing literature
- AutoNet and other stabilizing systems
6. Conclusions and Future Work
New powerline control, 10Mbps Phoneline Ethernet, intelligence moved to device and PCs evolve into in-wall console, digital video and music, broadband to home Web-based automation, telephony access, wireless LAN, computer vision, voice control,
Acknowledgements
The authors would like to express their sincere thanks to Pi-Yu Chung, Jeffrey Wang, and Andrew Wang for being willing to live with the Aladdin prototype and provide valuable feedback and bug reports; to Kuansan Wang for providing the natural language parser; to Victor Bahl for introducing us to the exciting world of home networking and for the inspiration on providing visual feedback as action confirmation; to Jeffrey Chirico, Mac Manson, Andrew Herb, and Doug Cannon for their help in setting up the Aladdin system; to Tim Osborne, Bradford Christian, Brian Christian, Mike Blaszczak, Martin Calsyn, and Brian Meyers for sharing their expertise and knowledge in powerline networking; to Dan Ling, Chuck Thacker, Ed Lazowska, Richard Newton, Raj Reddy, Andries van Dam, and the colleagues from the Systems and Networking Group at Microsoft Research for providing valuable feedback on an initial presentation, which has greatly helped us reshape the paper.
References:
[AnyPoint99] Intel AnyPoint Home Network, http://www.intel.com/anypoint/home.htm.
[Arora95] A. Arora and D. Poduska, “A timing-based schema for stabilizing information exchange in networks,” in Proc. of the Third International Conference on Computer Networks, Tokyo, Japan, 1995.
[Arora98a] Arora, A., and S. Kulkarni, “Component based design of multitolerance,” IEEE Transactions on Software Engineering, 24(1), 1998.
[Arora99] A. Arora, “Stabilization,” to appear in Encyclopedia of Distributed Computing, eds. Partha Dasgupta and Joe Urban, Kluwer Academic Publishers, 1999, http://www.cis.ohio-state.edu/~anish/group/papers.html
[Bahl00] P. Bahl and V. N. Padmanabhan, “User Location and Tracking in an In-Building Radio Network,” to appear in Proc. IEEE Infocom, March 2000.
[Czerwinski00] S. E. Czerwinski, B. Y. Zhao, T. D. Hodes, A. D. Joseph, and R. H. Katz, “An Architecture for a Secure Service Discovery Service,” in Proc. The Fifth Annual Int. Conf. On Mobile Computing and Networks (MobiCom’99), Aug. 1999, pp. 24-35.
[CM11A] CM11A Computer Interface, http://www.smarthome.com/1142.html.
[CM11ASpec] CM11A Programming Specification, ftp://ftp.x10-beta.com/ftp/protocol.txt.
[CM17A] FireCracker Computer Interface, http://www.x10.com/welcome/firecracker/free_fire_cm17a.htm
[HomePNA98] The Home Phoneline Networking Alliance, “Simple, High-Speed Ethernet Technology for the Home,” http://www.homepna.org/docs/wp1.pdf, June 1998.
[Slinke] Slink-e, http://www.nirvis.com/slink-e.htm
[SSDP99] Y. Y. Goland et al., Simple Service Discovery Protocol/1.0, http://search.ietf.org/internet-drafts/draft-cai-ssdp-v1-02.txt, June 1999.
[Waldo99] J. Waldo, “The Jini Architecture for Network-centric Computing,” Communications of the ACM, Vol. 42, No. 7, pp. 76-82, July 1999.
[X1099] Commercial X10 devices, http://www.smarthome.com/ or http://www.x10.com/.