Veri Bilimi İyi Alışkanlıklar
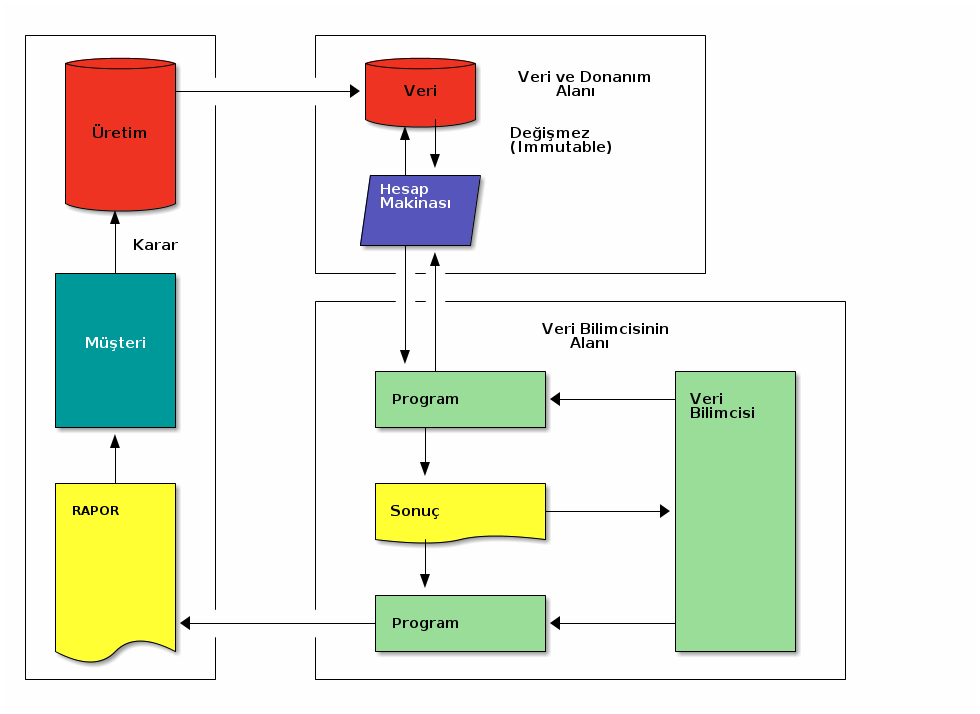
Veri bilimi uygulamaları genelde üç aşamadan oluşur:
- Eldeki veriler ile deneyler yapmak
- Deneylerin sonuçlarına göre yapılabilecek analizlere karar vermek
- Deney kodlarını kullanarak üzerinde rapor yazılacak analizler için gerçek kodun yazılması.
1 Prototip ve uygulama ayrımı
1.1 Prototip aşaması:
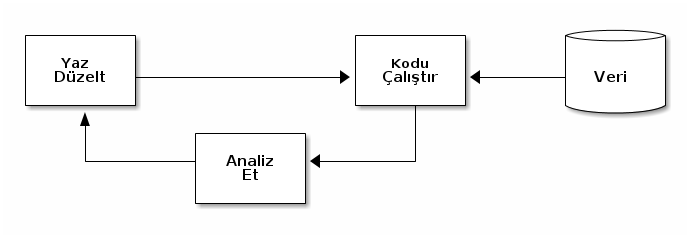
- Veri, yerel makinada dahi olsa değiştirilemez kabul edilmelidir.
- Bu aşamada verinin tamamı kullanılmak zorunda değildir. Prototip aşamasını hızlandırmak için verinin rastgele seçilmiş bir alt kümesi kullanılabilir.
- Verinin dönüştürülmesi gerekiyorsa mutlaka yeni bir kopyası yapılmalıdır. Asla eldeki verinin üzerine değişiklik yapılmamalıdır.
Kullanılan dilin
- esnek olması (mesela dynamically typed)
- defter (notebook) ya da REPL desteği vermesi
faydalı olacaktır. Örneğin: R, python, lisp, clojure.
- Yapılan her işlem, ya baştan otomatize edilmeli ya da her adım ayrıntılı bir şekilde raporlanmalıdır.
- Her deney kodu, ya elle numaralandırılmalı ya da bir sürüm kontrol yazılımıyla takip edilmelidir.
- Yazdığınız her şeyi bir iş arkadaşınızın okuyup takip etmeye çalışacağını düşünerek yazın. Bu iş arkadaşınız sizin 6 ay sonraki haliniz olabileceğini de unutmayın.
Always code as if the person who ends up maintaining your code is a violent psychopath who knows where you live.
1.2 Ürün aşaması:
Ürün aşamasında artık deneylerimiz bittiği ve ne yapacağımızı bildiğimiz için gerçek kodumuzu yazabiliriz.

Bu aşamada seçilecek dilin
- Veri analizimizin üzerinde çalıştırılacağı platform tarafından desteklenen
- Statically typed
- Debugging ve profiling destekleyen
bir dil olması tercih edilmelidir. Örneğin: C++, Java, Scala, Haskell.
2 Deney yapılırken dikkat edilmesi gereken noktalar
- Eğer veri ve kod aynı makina üzerinde olacaksa o zaman kod, veri ve raporların dizinlerinin ayrı olmasına dikkat edin.
- Eger veri üzerinde işlem uygulayacaksanız, ya da değişiklik yapacaksanız (örneğin veriyi temizlemek gibi) verinin yeni biçimi için yeni bir sürüm açın.
- Yaptığınız her deneyi, hem raporlayın, hem de açıklayın. Unutmayın ki, yazdığınız koda ve yeni ürettiğiniz veriye eninde sonunda geri dönüp bakacaksınız. Gelecekteki kendize iyi davranın.
- Raporları ve açıklamalarınızı deney sonuçlarından mümkünse kes/yapıştır yaparak yazmayın. Raporlarınızı ve açıklamalarınızı canlı kod içeren gerçek veri üzerinde çalışan programlarla hazırlamaya özen gösterin.
2.1 Otomasyon ve tekrarlanabilirlik
Kod otomasyonu için kullanılabilecek araçlar:
- R ya da python kullanıyorsanız o zaman
bash,zsh,perlya dapythonkullanabilirsiniz. - C ve C++ için kullanılan
make,cmakeve arkadaşları - java, scala ya da clojure kullanacaksanız
ant,gradle,sbt,leinengen,bootya da benzeri araçlar.
Raporlama için kullanılabilecek araçlar:
- Eğer R kullanıyorsanız
r-markdown,knitrya da üzerindeRçalışan jupyter defterlerini kullanabilirsiniz. - Eğer
pythonkullanıyorsanız o zaman üzerindepythonçalışanjupyterdefteri kullanın. - Eğer
emacskullanmaya alışıksanız, o zaman raporlarınız içinorg-modekullanabilirsiniz. - Eğer deney sonuçlarınızı bir akademik makale içinde
kullanacaksanız \laTeX\ ve
sweavekullanmanızı öneririm.
2.2 Defterler
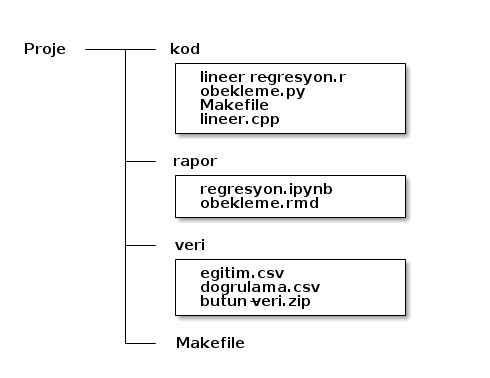
2.3 Kod ve veri ayrımı
Bir veri analizcisinin proje dizini şöyle görünebilir:
2.4 Sürüm numalama (git ve arkadaşları)
Git bir sürüm kontrol sistemidir. Bir dizin içindeki dosyaları takip eder. Aşağıda git'in takip ettiği bir dosyanın olabileceği durumların bir diagramını görmektesiniz.
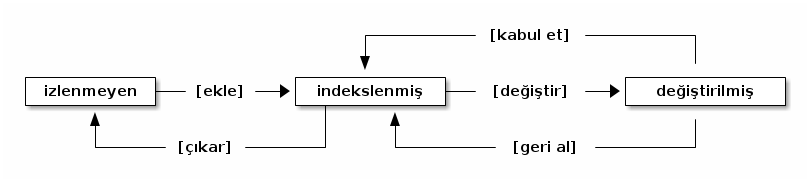
Komutlar:
- Sıfırdan başla:
git init - Ekle:
git add <dosya ad(lar)ı> - Çıkar:
git rm --cached <dosya ad(lar)ı> - Kabul et:
git commit <dosya ad(lar)ı> -m <açıklama> - Geri al:
git checkout <dosya ad(lar)ı>
2.5 Eğitim ve değerlendirme verilerinin ayrılması
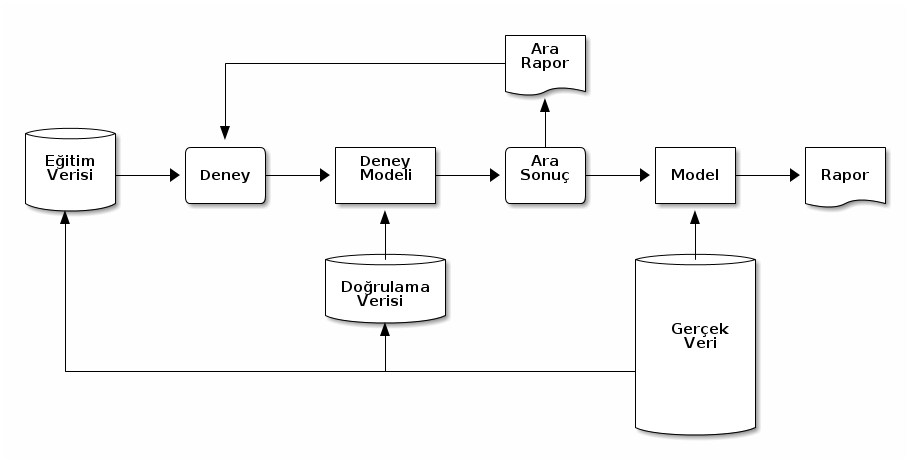
- Size deney yapmanız için verilen veriyi iki parçaya bölün: eğitim verisi ve doğrulama verisi.
data <- read.csv("veri/butun-veri.csv", sep=",", header=TRUE)
N <- nrow(data)
sec <- sample(1:N, 0.02*N, replace=FALSE)
altkume <- data[sec,]
M <- nrow(altkume)
secsec <- sample(1:M, 0.3*M, replace=FALSE)
egitim <- altkume[secsec,]
write.csv(egitim, file="data/egitim.csv", sep=",", header=TRUE)
dogrulama <- altkume[-secsec,]
write.csv(dogrulama, file="data/dogrulama.csv", sep=",", header=TRUE)
- Eğitim verisinden bir model oluşturun. Bu modelin iyi çalışıp çalışmadığını doğrulama verisi üzerinde test edin.
D <- nrow(dogrulama)
model <- glm( y ~ x , data=egitim, family="gaussian")
sonuc <- predict(model, dogrulama$x)
hata <- (1/D)*sqrt(sum(sapply(sonuc-dogrulama$y, function(u) { u*u })))
- Elinizdeki modelin iyi çalıştığından emin olunca gerçek veri (production data) üzerine taşıyın.
sonuc <- predict(model, data$x)
- Raporlarınızı ara sonuçları çıkarmak için kullandığınız programdan elde ettiğiniz bir programlamla çıkarın.
3 Deneyler bitti, modelimizi kurduk. Sırada ne var?
3.1 Raporlama
Deneylerden bir model çıkarttınız. Bu modeli elinizdeki doğrulama verisi üzerinde test ettiniz. Çıkan sonuçlardan elinizdeki modelin istatiksel olarak iyi bir model oluşturduğuna karar verdiniz. Elinizdeki modeli gerçek veri üzerinde çalıştıracaksınız. Ancak bu sonuçların verinin sahibi ve veriden eldek edilecek sonuçları kullanacak olan kişi ve kurumlara onların anlayabileceği bir şekilde anlatılması gerekir.
3.2 Basit bir örnek
Varsayalım ki elimizde bir web sitesini ziyaret etmiş bir grup kullanıcı verisi olsun. Varsayalım ki sunucu bu kullanıcılara aynı sayfanın iki değişik şeklini sunmuş olsun: A ve B. Yine varsayalım ki, elimizde bu kullanıcıların belli bir reklam linkine basıp basmadıklarının bilgisi de olsun.
head(data) Tipi Link 1 A Basmadi 2 A Basti 3 A Basmadi 4 B Basmadi 5 A Basti 6 B Basti
Bizden istenen, sitenin şeklinin reklamlara basma davranışı üzerinde bir etkisi olup olmadığını test etmek olsun.
sonuc <- table(data)
sonuc
Link
Tipi Basmadi Basti
A 24 4
B 99 11
İlk bakışta A tipi sayfanın reklam linkleri konusunda başarılı sonuç verdiği görülse de (A'da 4/28 = 0.14 başarı oranına rağmen, B'de bu oran 11/110 = 0.10 olarak görünüyor) bunu daha dikkatli analiz ettiğimizde görüyoruz ki
karsilastirma <- binom.test(4,28,p=11/110)
karsilastirma
Exact binomial test
data: 4 and 28
number of successes = 4, number of trials = 28, p-value = 0.5206
alternative hypothesis: true probability of success is not equal to 0.1
95 percent confidence interval:
0.04033563 0.32665267
sample estimates:
probability of success
0.1428571
elimizdeki veri web sitesinin A ve B tipi biçiminin reklamlar konusunda farklı sonuçlar verdiğinden emin olamıyoruz. Daha fazla veri toplamamız gerekiyor. Ne kadar veriye ihtiyacımız var?
nekadar <- power.prop.test(p1=0.14,p2=0.10,sig.level=0.05,power=0.9,alt="one.sided")
nekadar
Two-sample comparison of proportions power calculation
n = 1128.552
p1 = 0.14
p2 = 0.1
sig.level = 0.05
power = 0.9
alternative = one.sided
NOTE: n is number in *each* group
Bu sonucu raporlarsak şu şekilde sunabiliriz (r-markdown)
Elimizdeki veri web sitesinin A tipi biçiminde reklamlara basma oranını yüzde `r floor(100*sonuc[1,2]/sum(sonuc[1,]))` ve B tipi biçiminde reklamlara basma oranını da `r sonuc[2,2]/sum(sonuc[2,])` olarak göstermektedir. Ancak bu sonuçları istatiksel olarak karşılaştırdığımızda A tipi sayfada reklamlara basma oranının gerçek değerinin yüzde `r floor(100*karsilastirma$conf.int[1])` ile yüzde `r floor(100*karsilastirma$conf[2])` arasinda olduğunu görmekteyiz. İstatiksel olarak sağlıklı bir sonuç alabilmemiz için web sitesinin her iki şekli için en az `r floor(nekadar$n)` tane veri noktasına ihtiyacımız bulunmaktadır. Bu durumda elimizdekı veri, A tipi sayfanın daha iyi sonuç verdiği konusunda olumlu işaretler verse de kesin bir sonuç çıkartamıyoruz. Sayfa düzeninin şu anda değiştirilmemesini, ancak daha sağlıklı bir analiz için eldeki deneylerden daha fazla veri toplanmasını öneriyoruz.
Yukarıdaki rapor şu şekilde görünecektir:
Elimizdeki veri web sitesinin A tipi biçiminde reklamlara basma oranını yüzde 14 ve B tipi biçiminde reklamlara basma oranını da yüzde 10 olarak göstermektedir. Ancak bu sonuçları istatiksel olarak karşılaştırdığımızda A tipi sayfada reklamlara basma oranının gerçek değerinin yüzde 4 ile yüzde 32 arasinda olduğunu görmekteyiz. İstatiksel olarak sağlıklı bir sonuç alabilmemiz için web sitesinin her iki şekli için en az 1128 tane veri noktasına ihtiyacımız bulunmaktadır.
Bu durumda elimizdeki veri A tipi sayfanın daha iyi sonuç verdiği konusunda olumlu işaretler verse de kesin bir sonuç çıkartamıyoruz. Sayfa düzeninin şu anda değiştirilmemesini ancak daha sağlıklı bir analiz için eldeki deneylerden daha fazla veri toplanmasını öneriyoruz.